文字コード(SQLite)
SQLiteを使って、また文字コードが分からなくなりました。
移行のために、SQL文の入ったUTF-8のファイルをphpMyAdminで作りました。これを、SQLiteの入力にします。
WindowsのDOS窓で使う、xamppliteに含まれるsqlite.exeは、操作はSJISです。でも、UTF-8のSQL文のファイルを処理できるのです。
当然ながら、UTF-8のデータを表示すれば化けて見えます。コードに関わらず、そのまま格納すると考えれば説明が付きます。
- 入力するファイルには、格納する文字列だけでなく、INSERT INTO なども書かれているわけですが、なぜ問題ないのか?
- コンソールとのやりとりは、SJISだと思いますが、DLLとのインタフェースは、どうなっているのでしょうか? 何かのコードに変換するとすると現象と合いません。
- また、Unicodeを渡す場合、DLLとのインタフェースには標準的な方法があるのでしょうか?
1.Unicode関連の用語
- 分類と符号化の分離
文字コードの規格には枝番や追加仕様がよくあるので、Unicode、UTF-8,...もそうしたものだと誤解していました。Unicodeは、形状に一意な番号を与えることと、それを符号化することを分離した規格です。単にUnicodeというう時には、符号化されていない一意な番号のことだと考えれば良さそうです。
ただし、Windowsの世界では、UnicodeはUSC-2(後述)の意味でも使われます。
- Windowsの文字コード
Windowsの内部では、2バイト固定長のUnicodeが使われています。Windows上で開発したプログラムなら、DLLの呼び出しなどでも、このコードが使われます。
しかし、これはWindowsだけのルールだと考えられます。このコード自体はファイルに書いたり、伝送するのにほとんど使われていないのと、名前を知らないことがそう考える理由です。
では、このC#のstring型のデータなどは何なのでしょうか。調べてみると、UCS-2、あるいはUnicode2.0と呼べば良さそうです。
UCS-2は、ISO10646の解説にあったもので、UCS-2とUCS-4があり、2バイト、4バイトの固定長です。Unicode2.0も2バイトの固定長です。
Unicode自体は、現状では可変長コードになっていると言うことのようです。
- BMP(Basic Multilingual Plane)
現在も有効なのかどうかは分かりませんが、「UnicodeのBMP」と言う記述があり、これは、UCS-2と言うことのUnicodeでの呼称のようです。
第0面(0-0xffff)を示します。
- UTF-8は、Unicodeを符号化したものです。Unicode自体は、バイト列から文字を認識する方法がないので、固定長にするか別途情報を持つ必要があります。これを交換用に符号化します。符号化の結果は、可変長になります。連続した1の個数で文字の長さが分かるようになっています。
- UTF-8の符号化は、0から0x7fの間のコードは元の値と同じになることを意図しています。この間のコードは、ASCIIコードと一致します。したがって、0から0x7fの間の(半角の英数記号など)から成るファイルは、UTF-8、ASCII、Latin1、SJIS、EUC、いずれでも同じになる(区別がない)と言うことです。(ただし、UTF-8にはBOM付の場合がある。)
- また、0x7f以上は符号化の結果にゼロのバイトが出現しません。(ゼロを終端と見なす扱い方が有効です。)
- UTF-8はUCS-4を符号化することを意図して、6バイトまでの符号化が定められていますが、実際には、4バイトまでが使われているようです。
- BOM (Byte Order Mark)
Windows上のテキストエディタで、「あ」だけを書いたUTF-8 BOM付ファイルを書いてみると、
EF BB BF E3 81 82
と、なります。
UTF-8からUnicodeにデコードすると、
FE FF 30 42
と、なります。
0xfeffは、UNICODE3.1でBOMに割り当てられ、ISO10646では無機能な文字と決められてるようです。また、0xfffeは共に未定義なようです。
「あ」は、0x3042です。UTF-8ではバイトオーダーに関係なく同じです。
- UTF-8のBOM
UTF-8のファイルであることを示す意味合いで使われるのだと思います。
PHPのソースコードをBOM付で保存すると動作しませんでした。WWWの世界では、BOMは邪魔者のようです。
C#で作成したファイルはBOM付のUTF-8のファイルになります。普段はプログラムが扱うコード系に関心を持ちますが、プログラムそのものがどんなコードで保存されているのかも重要です。プログラムのコメントは処理に関係ないものと考えていましたが、コメントに全角スペースが1つあるだけでコンパイラの処理が変わることになります。認識したコード系に応じて、文字リテラルを、プログラムが扱うコード系に変換することになります。このコード系の認識を「自動認識」にゆだねるわけにはいかないと考えます。
- MySQLには、良くLatin1という名称が出てきます。ISO8859-1の別名のようです。
- Latin1の日本語
MySQLとphpMyAdminの間の文字化けを調べて知ったのは、Latin1として日本語が扱えていると言うことです。
PHPでプログラムを書いたり、既存のPHPプログラムでMySQLを使うのはなんら問題ないが、phpMyAdminだけが文字化けしているケースでは、Latin1として日本語が扱われているためです。理由はわかりませんが、入力時に各バイトを、UnicodeからUTF-8にエンコードするのと同じようにエンコードしています。出力時には、Latin1を設定すると、デコードします。したがって、入力と同じ状態が復元され文字化けしません。
phpMyAdminは、出力時にUTF-8を設定しています。すると、MySQLは格納した(エンコードした)データをそのまま出力します。したがって文字化けします。
これは単に何かの間違いのように思うのですが、現実にたくさんのデータベースがこの状態で使われているのではないかと思うのです。データベースの中身の問題なので、入れ替えない限りUTF-8にはなりません。
今回、SQLiteの挙動を見て、同じことがあるのではと心配しています。
- Encoding.Unicodeプロパティの説明が「リトル エンディアン バイト順を使用する UTF-16 形式」となっているのを知りました。
UTF-16は2バイトか4バイトです。Windowsの内部コードは本当に2バイトかと突き詰められると本当は自信がありません。
結局はっきりしたことはわからないのですが、string型などC#の内部の文字コードをUCS-2と呼ぶことにします。
2.現象の確認
insert into simple values (1,'あ');
のようなINSERT文を書いて、UTF-8(BOMなし)とSJISで、それぞれ utf8.sql、sjis.sql に保存しました。
これを、DOS窓で、読み込ませて見ます。
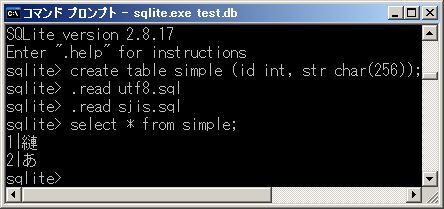
DOS窓はSJISを表示するので、UTF-8で格納したデータが化けているのだと思います。
おそらく、データの内容はそのまま格納されるのだと考えました。
同じことをUTF-8がネイティブのLinuxでやってみました。

反対に化けています。
sqlite.dll を呼び出すC#のプログラムを書いてみました。
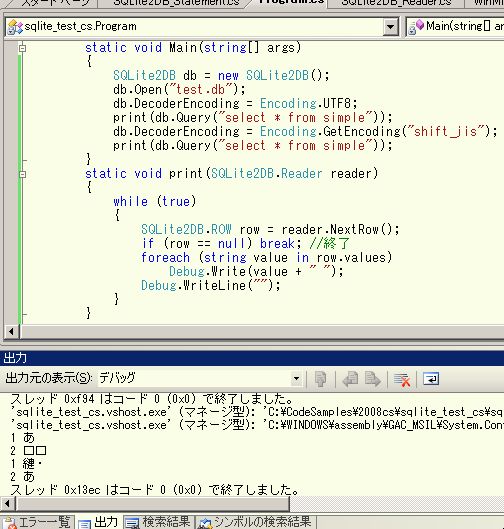
SQLite2DBクラスにある、DecoderEncoding は、sqlite.dllから文字列を受け取った場合にだけ使います。
受け取ったバイト列が、SJISなのかUTF-8なのかを指定します。
stringクラスのコンストラクタには、
public String(
sbyte* value,
int startIndex,
int length,
Encoding enc
)
が、あります。このencに使います。
このコンストラクタは、「バイト列valueはenc文字セットなので、内部コード(UCS-2)に変換してください」と言うことです。
データに関しては扱いがわかりました。
このプログラムを修正しながら以下のことを調べてみます。
・データの渡し方
このプログラムでは、
[In, MarshalAs(UnmanagedType.LPStr)] と指定してASCIIへのマーシャリングが行われています。全角文字やバイナリはどうでしょう?
・データは検索や並べ替えができなければなりません。何でもそのまま入るだけでは済まないのでどうなっているのでしょうか?
・フィールド名やテーブル名などに全角文字を使うのはどうでしょう?
下の図は、UTF-8のLinuxで、SQLをコンパイルする処理に渡されている文字列を、文字と16進で表示したものです。
sqlite> .read utf8.sql
insert into simple values (1,'\u3042');
69 6e 73 65 72 74 20 69 6e 74 6f 20 73 69 6d 70 6c 65 20 76 61 6c 75 65 73 20 28 31 2c 27 e3 81 82 27 29 3b
sqlite> .read sjis.sql
insert into simple values (2,'\ufffd\ufffd');
69 6e 73 65 72 74 20 69 6e 74 6f 20 73 69 6d 70 6c 65 20 76 61 6c 75 65 73 20 28 32 2c 27 82 a0 27 29 3b
sqlite>
文字列表示に \u3042 などの表示がありますが、printf()で文字列を書き出すと自動的に変換して表示されています。入力は、"あ"です。
valusのカッコ内の"あ"の部分は、入力ファイルの通りで、それぞれUTF-8、SJISの"あ"のコードになっています。
e3 81 82
82 a0
下図は、C#で作成したプログラムから、C++のDLLを呼び出す場合の変換の確認です。
insert into simple values (1,'あ');
69 6e 73 65 72 74 20 69 6e 74 6f 20 73 69 6d 70 6c 65 20 76 61 6c 75 65 73 20 28 31 2c 27 82 a0 27 29 3b
この例は、[In, MarshalAs(UnmanagedType.LPStr)] と書いてstringを自動的にマーシャリングした例です。C#の内部コードのUCS-2からSJISに変換されています。
下図は、[In, MarshalAs(UnmanagedType.LPWStr)] と書いて、stringを自動的にマーシャリングした例です。
69 0 6e 0 73 0 65 0 72 0 74 0 20 0 69 0 6e 0 74 0 6f 0 20 0 73 0 69 0 6d 0 70 0
6c 0 65 0 20 0 76 0 61 0 6c 0 75 0 65 0 73 0 20 0 28 0 31 0 2c 0 27 0 42 30 27 0
29 0 3b
UCS-2のまま渡されます。これは文字列中にゼロを含むので、sqlite.dll内部では扱えません。
3.入力するファイルには、格納する文字列だけでなく、INSERT INTO なども
書かれているわけですが、なぜ問題ないのか?
sqlite.dllが受け取る文字列は、0から0x7fは、ASCIIで、ゼロが終端として使えるコード系と言うことのようです。
SQL文のSELECTなどの予約語やクオートが同じなら、クオート内は無変換で扱えば良いと言うことです。
UTF-8の場合は、全角文字は全てのバイトが0x80以上になるので問題ありません。EUCもOKです。
SJISの場合は2バイト目がASCIIと重なる場合があります。ただし、0x40以上なので、クオート文字とは重ならないと言うことです。
4.コンソールとのやりとりは、SJISだと思いますが、DLLとのインタフェースは、
どうなっているのでしょうか? 何かのコードに変換するとすると現象と合いません。
ほぼ、そのままスルーだと言うことのようです。sqlitedll内にではコード変換はされないようです。
5.Unicodeを渡す場合、DLLとのインタフェースには標準的な方法があるのでしょうか?
UnmanagedType.LPWStrのマーシャリングは、Windows以外では使われないと思います。OS内部がUCS-2で無い限り、他のコードと混在できません。
したがって、UnicodeをUTF-8などにエンコードしたコードが使われるのは必然だと思います。エンコード方法のうち、現実に使われているのはUTF-8だと思います。一見Unicodeの色々なエンコード方法がサポートされるように書かれていますが、エンコード方法をデータから確実に知る方法が無い以上、何かを標準と決める必要があるからです。
C#では、
byte[] b = Encoding.UTF8.GetBytes(sql);
のようにして、UCS-2のstringから、UTF-8にエンコードしたバイト列が得られます。これを使うことにします。
|