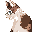振幅波形の伸縮(sinc)
振幅波形データを任意のサンプル数に変換するのに便利です。
少ないサンプル数でプロットするとき、曲線を滑らかにできます。
R言語のコンソールで、resample と打ち込むとresample()のスクリプトが表示されます。
この後半部分を仕組みも知らずに使っていました。
演算
他のリサンプルの方法と同様で、前後のサンプルに距離に応じた重みを掛けて加算する方法です。
order = 5 がデフォルトで、前後のそれぞれorderサンプルから出力値が計算されます。
最初に出力の長さのインデックスを作っています。これは、入力のサンプルをインデックスする連番ですが、サンプル数を増やす場合は重複があり、減らす場合は欠番があります。
この出力の長さのインデックスの順番がX座標で、その座標の振幅を求めることになります。インデックス値は、入力サンプルの順番を指しますが、計算は倍率を元に計算され端数があります。この端数は、X座標と入力サンプルの距離を示します。
このX座標と入力サンプルの距離と、出力の長さのインデックスから、2・order+1回のループで演算しています。
各出力サンプルには、結果的に、それぞれ 2・order+1種類の係数が乗じられた2・order+1ポイントの和が求められます。
R言語のコンソールで、resample と打ち込むとresample()のスクリプトが表示されます。
ここには理解できた範囲で、出力サンプル数を指定する関数にしたものを載せます。
- # 数列 x を、長さ oc に伸縮する。
- fit_length <- function(s,oc)
- {
- order <- 5 # 前後に、それぞれorderサンプルを使って補完
- # 出力と同じ長さの数列。順番が出力のX座標。
- x <- seq(0,by=length(s)/oc,length.out=oc)
- # 入力サンプルを示すインデックスにする。小数点以下切り捨て。ゼロ始まり。
- xi <- trunc(x)
- # 出力の座標ととサンプリングポイントのX方向の距離
- xd <- x - xi
- # 計算結果の格納場所
- y <- rep(0,oc)
- # 計算の都合で入力の前後にそれぞれorder個のゼロを付加
- s <- c(rep(0,order), s, rep(0,order))
- # -orderからorderまでずらしながら係数列を掛け、加算
- for(i in (-order):order)
- {
- w <- sinc(xd - i) * (0.5 + 0.5 * cos(pi * (xd - i)/(order + 0.5)))
- w <- ifelse(is.nan(w),1,w)
- y <- y + s[xi + i + order + 1] * w
- }
- y
- }
カーディナル・サイン
 まず、sinc() がどんなものか見ておきます。 まず、sinc() がどんなものか見ておきます。
sinc(x) = sin(π・x) / π・x
で、sinc(0) = 1 のようです。
R言語の sinc(0) は、NaN になります。
Octaveでは、1 になります。
分子は、[-1,1]で、分母はゼロを挟んで絶対値が大きくなるので、減衰していきます。
係数列
係数列は、求める位置からの距離に応じて重み付けすることが目的です。
スクリプトでは、これを求める位置ごとではなく、距離ごとに 2・order+1回ループで計算しています。
ここでは、ある求める位置に対して、前後のサンプルにどんな係数が乗じられているのか見てみます。
サンプルの長さを変更する割合が 0.5 から 2 なら、最も近い入出力のサンプル間の距離は1以上開かないので、前後に order の距離を見ます。
左図は、order=5 で、重みとして使われる値を黒でプロットしています。
緑は、重みの計算のsinc()部分で、ゼロ近傍では重みと重なっています。
赤は、重みの計算の残りの部分です。sinc()を距離に応じて、さらに減衰させるもののようです。
これは、ハン窓の両端をわずかに削ったものです。
分割して処理するために
C#で書いて、Silverlightアプリケーションにして置きます。
リアルタイムな処理や利便性を考えて、全体を一回で変換するのではなく、分割して処理できるようにします。
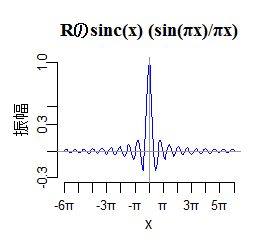
リサンプル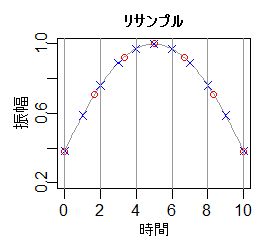
リサンプルは、サンプル数の変換と考えることにします。
入力と出力のサンプル数の総数で変換率 R を決めることにします。
もし、総数がわからない場合は、両者のサンプリングポイントが一致する間の長さを使います。
R = 出力サンプル数 / 入力サンプル数
左図で、青が入力、赤が出力の場合を考えます。
変換率は、R=6/10 や R=3/5 と指定することになります。
時間軸
水平方向を時間、垂直方向を振幅としたXY平面で考えます。
x軸は、出力のサンプル間隔を1とします。最初の入出力サンプルは、ゼロから始まるものとします。
出力のサンプル間隔は、1/R です。
上の図の場合、5/3 が、出力のサンプリング間隔になります。
処理単位と時間
分割して処理する場合の処理単位は、任意のサンプル数 N とします。
出力は、N・R サンプルです。N・Rは整数になるとは限らないので、前回の処理結果の影響を受けます。
入力の時間は、整数値なので、毎回先頭をゼロとした相対的な時間で考えます。
これに対して、出力の処理単位の先頭は、前回の終了からの差を考慮する必要があります。
もともと、この操作は前後の数サンプルを必要とするので、入力の後端部分は次回の処理に残すことが必要です。
出力バッファと、その位置(op)はこの操作を行うクラスで管理することにします。
時間については、出力時間の積算値(To)を持つことにします。
入力の座標とデルタ
出力サンプルのX座標は、To - trunc(To) 、To の整数部分を除いた値が初期値で、1/R間隔になります。
この算出値の整数部を、直近の入力サンプルを取得するインデックスとします。
また、小数点以下は、入力サンプルとの差 Δx を表します。
補間には、近傍の入力サンプルの他、前後の数サンプルを参照しますが、入力のサンプリング間隔は1なので容易に座標が計算できます。
近傍の数サンプル

ある時刻(あるX座標)のサンプルを算出するには、近傍の入力サンプル列が必要です。
1つのサンプルの出力のために、前後にSサンプル参照する場合、計算に使うレジスタを左図のように構成してみます。
レジスタは、6つの部分(Sl,Sa,Sx,Sb,Sc,Sr)から成ります。
Sx を除く Sl,Sa,Sb,Sc,Sr は、長さが Sサンプル です。
初回は、Sl、Sa にゼロを詰めて始めます。
後端は、Sサンプル不足するので、不足が生じたら打ち切ります。
2回目以降は、初回の入力から2Sサンプルを繰り越して連結して使います。
以上が概要です。実際には、出力の時刻は整数ではないので、レジスタの各部位の開始位置は固定ではありません。
|