似た文字、異体字、旧字
「日」と「曰」は、似ているが区別されるべき文字のようです。後者は、漢文訓読で出てくる「曰(いわ)く」です。前者の日(ひ)は、象形です。後者の曰(いわく)は、会意で口と、口の中からことばが出てくることを示す記号からできているのだと漢和辞典にあります。
しかし、曰(いわく)が日常使用されることはなく、書き手や読み手が字形で区別出来ているのかどうかも定かではありません。やはり、明瞭に区別がつく字形を常用するのが原則だと思います。
「學」は「学」の旧字だと思います。近年国内の事情で簡略化した文字には漢字圏では使用されないものがあると推測しますが、Unicodeに各国規格との対応があり、概ね使用されているようです。
「籌算(ちゅうさん)」は広辞苑に「数をかぞえること、そろばん、はかりごと」などとあります。竹冠を取った「壽」は「寿」の旧字なので、筹算(チョウザン)が使用されています。したがって、「籌」は「筹」の旧字と言えますが、国内では「筹」は使われていないようで、私の使っている辞書にはありません。「籌」が既に日常使われないので新字体にする必要もないと言うことだと思います。他の漢字のパーツとなっている文字を新字体にすると派生的に新たな漢字が誕生します。
旧字体とか新字体と言うのは経緯の分かる間だけ言えることで、「異体字」の中にはかつての旧字、新字が含まれているものと思います。おそらく、「異体字」は、由来の異なるパーツの組合せだが同義に使用される比較的形が似た文字のことだろうと思います。しかし、多くの場合、古い辞書から引き継がれていることなのだろうと思います。
「筭」は「算」の異体字です。漢和辞典では解字で前者の文字が説明されています。会意文字で竹+具と説明され後者に結びつきます。
「野」「㙒」「墅」「埜」「壄」「𡐨」「𡑀」「𤝉」は、異体字です。辞書には「埜」は「野」の旧字や古字と説明があります。
「崎」「嵜」も異字体です。「崎」はUnicodeに漢字圏各国規格との対応が収録されていて一般的なようです。「嵜」はUnicodeにGB16500-95とJIS X 0208-1990との対応だけがあり、主に国内で使用されているようです。
もう一つの「異体字」は、IMEパッドの「手書き入力」にあります。「埜」と字形を描いて、選択された文字の一覧の「埜」の上で右ボタンメニュー(コンテキストメニュー)を出すと「異体字」があります。選択すると「野」、「壄」が入力できます。
新字体
1923年(大正12年)に「常用漢字表」が示され、簡略化した書体が常用されるようになったようです。国内で作られた文字になる訳ですが、多くの文字は漢字圏で通用しているようです。 
「禮」は「礼」の旧字ですが、漢和辞典に「礼」は「古文の字体」とあります。しかし、この「古文は字体」は国字を意味していないようです。「礼」は「れ」の元字なので「礼」は、近代になって作られた文字ではないと考えられます。
「礼」は「説文解字」にあるもある文字で、このとき既に異字体であったようです。
日本では「藝」は「芸」ですが、「艺」が使用されているようです。「芸」は略字ではなくもともとある字形で、日本以外の漢字圏では人名等に使用されている文字なので「艺」の略字を作ったと言うことのようです。JIS漢字として「艺」はありません。Unicodeでは、827aの艺には、JISの対応文字がありません。82b8の芸には、JISを含めた漢字圏が自国規格との対応文字を規定しています。「芸」は、日本だけが「藝」で、他の漢字圏では「蕓」の異字体に見えると言うことのようです。
1923年より前の文書の「芸」は、「ウン、くさぎる、アブラナ」(「くさぎる」は草を刈ることらしい)と言うことになります。論語微子篇7に「植其杖而芸」とあり、日本では「杖を立てて(植)くさぎる(芸)」と訓示られて来たようです。
文字セット
文字には考えが及ばないほどたくさんの用途や利用環境があります。万能なものが望めないことは分かっている訳ですが、何とかしないと不便です。
Unicodeは、文書に使用された文字の字形を集めることを目的としているようです。文字の意味や類似性を議論していては進みません。実在する文書に使われている字形が違っていたら収集していくことになります。しかし、文字はグループ化されていて、収集の状況には揺らぎがあるようです。
ようやく、申請単位から来る区画とは無関係に漢字を使うことがはっきりしてきたのではないかと思います。したがって、文字の属性データが重要になっていくのだと思います。
インターネット検索は優秀で、数字は漢数字でも一致し、かなで漢字がヒットしたりもします。これは意味解釈もしているからで、必ずしも文字列一致の話しではありませんが、文字属性も重要です。
漢字を漢字圏全体で捉えると、大半の漢字が日本では未使用だと言うことになります。「𤝉」は、日本では使われないようですが、もし使われれば「の」と訓じられることになります。
私には、「野」と「㙒」を区別して使う必要性は全くありません。しかし、文書を原文に近い形で表すために使われることも理解できます。ただ、どんなに沢山文字を作っても文字コードでは表現しきれないことも確かです。また、「日」と「曰」のように、字形だけで判断できないものもあります。
大量のフォントが扱えるようになったことは、画像も扱えることなので、もっと写真等を活用する必要があるのだと思います。文字コード列に依る表現には大きなメリットがある訳で、そのメリットが生きるような割り切りが必要なのだと思います。
日本には訓があるように各国の事情によって漢字を含む文字コード系は定められ、Unicodeにも反映されています。日本のJIS、台湾のBIG5(大五碼)、CNS((Chinese National Standard)、中国のBG(Guójiā biāozhǔn(国家标准、国家標準))があります。
Unicodeの漢字の区画は「CJK」で始まる名前が付いていますが、中国、日本、韓国、(ベトナム)のことらしく、CJK統合漢字として収録することとしているようです。
したがって、これらの国の文字コードとの対応が定まっていることになります。しかし、JIS X 0213 (第一、第二水準漢字、第三、第四水準漢字)は、1万字を超えていて日常使用する文字の基準にはならないようです。
常用漢字
現在の「常用漢字表」は2010年告示された2136字のようです。
良く取り上げられているのが「𠮟(しかる)」で、「叱」ではないと言うことです。常用漢字が採用したのが「口+七(漢数字)」で、後者の「叱」は「口+(切るの原字)」のようです。パソコンでは後者が使われています。これは、後者はJISの第一水準漢字にあり、常用漢字が採用した「𠮟」は、2000年以降に加えられたものです。
常用漢字表に、「口+七(漢数字)」と書かれたり、文字コードとの対応を述べている訳ではないようです。表の文字1つを見つめていても私には区別ができないので、真偽は良く分かりません。
常用漢字表には「亜(亞)」のように異字体も示されています。「𠮟(しかる)」が同じように併記されなかったことは、単に区別がされていないだけなのかもしれません。
しかし、専門家が間違うはずがないと考えると、併記しないのは字形が似すぎていて、両方を常用漢字として併用するのは適切でないと考えた、と言う推測です。
電子化された文書では、既にJIS第一水準が使用されていることを考慮しても、「𠮟(しかる)」を取るべきだと判断されたことになりますが、これもありそうには思えません。
文化庁が公開している「常用漢字表」は、PDFファイルです。字形は絵ではなく、文字コードなので、コピーできます。したがって、文字コードを知ることが出来ます。
ただし、亀の異体字の「龜」は例外です。PDFへフォントを埋め込んであるのだと思いますが理由は分かりません。
このことは、常用漢字は、パソコンに一般的なフォントで良いと判断されたものと推測できます。当然、常用される文字のフォントはパソコンにもあるはずで妥当です。
常用漢字表はパソコンの文字、あるいはJIS漢字で字形を示していて、文字コードも定まっていると見て良いものと思います。
何の説明も付されていないようですが、常用漢字表の文字には並んで括弧書きで異字体が記されたものがあります。おそらく、旧字なのだと思います。
旧字も常用されたものでなければならないはずで、たくさんある異字体の中で国内で使用頻度の高いものと理解して良いのだろうと思います。
常用漢字の異体字(1:1)
亜悪圧囲医為壱逸隠栄営衛駅謁円塩縁艶応欧殴桜奥横温穏仮価禍画会悔海絵壊懐慨概拡殻覚学岳楽喝渇褐
亞惡壓圍醫爲壹逸隱榮營衞驛謁圓鹽緣艷應歐毆櫻奧橫溫穩假價禍畫會悔海繪壞懷慨槪擴殼覺學嶽樂喝渴褐 |
弁だけは、辨瓣辯と3つの異字体が上げられています。
また、以下のような「許容字体」が上げられています。おそらく、何らかの基準で異体字の原因が書き誤りにあると考えられると言うことだろうと推測します。
おそらく、旧字も許容字体も使用頻度があって、「常用」と判断されると言うことだと思います。
異字体も含めた常用漢字表の文字のうち第一水準は2115、第二水準は308で、それ以外から85文字が採られています。この文字は、JISの第三水準に割り当てられた文字のようです。
このうち「𠮟」だけは、UnicodeのBMPの外に割り当てられています。windowsではサロゲートペアの4バイト表現になるのでプログラミング上では注意が必要です。
「𠮟」は、u20b9fで、面区点1-47-52(4f54)です。
JISの第三水準にある常用漢字85文字のうち、「𠮟」以外の文字84文字を下表に示します。
常用漢字のうち第三水準にあるもの(𠮟を除く)
| UCS |
| 逸 |
1-92-57 |
fa62 |
謁 |
1-92-15 |
7de3 |
緣 |
1-90-13 |
6eab |
溫 |
1-86-92 |
| 禍 |
1-89-31 |
fa3d |
悔 |
1-84-48 |
fa45 |
海 |
1-86-73 |
fa3e |
慨 |
1-84-60 |
| 槪 |
1-86-04 |
fa36 |
喝 |
1-15-12 |
6e34 |
渴 |
1-86-88 |
fa60 |
褐 |
1-91-79 |
| 漢 |
1-87-05 |
fa4e |
祈 |
1-89-23 |
fa42 |
既 |
1-85-11 |
fa38 |
器 |
1-15-22 |
| 虛 |
1-91-46 |
fa69 |
響 |
1-93-86 |
fa34 |
勤 |
1-14-72 |
fa63 |
謹 |
1-92-16 |
| 揭 |
1-84-83 |
64ca |
擊 |
1-85-02 |
784f |
硏 |
1-89-03 |
9ec3 |
黃 |
1-94-81 |
| 穀 |
1-89-45 |
f970 |
殺 |
1-86-41 |
fa4d |
祉 |
1-89-20 |
fa61 |
視 |
1-91-89 |
| 社 |
1-89-19 |
fa5b |
者 |
1-90-36 |
fa48 |
煮 |
1-87-53 |
fa5c |
臭 |
1-90-56 |
| 祝 |
1-89-27 |
fa43 |
暑 |
1-85-35 |
fa5a |
署 |
1-90-26 |
6d89 |
涉 |
1-86-76 |
| 狀 |
1-87-74 |
fa56 |
節 |
1-89-68 |
fa50 |
祖 |
1-89-25 |
5de2 |
巢 |
1-84-08 |
| 瘦 |
1-94-93 |
fa31 |
僧 |
1-14-41 |
fa3b |
層 |
1-47-65 |
fa3f |
憎 |
1-84-62 |
| 贈 |
1-92-29 |
537d |
卽 |
1-14-81 |
fa37 |
嘆 |
1-15-15 |
fa5f |
著 |
1-91-07 |
| 徵 |
1-84-36 |
fa40 |
懲 |
1-84-65 |
5861 |
塡 |
1-15-56 |
9b2d |
鬭 |
1-94-31 |
| 突 |
1-89-49 |
fa68 |
難 |
1-93-67 |
fa44 |
梅 |
1-85-69 |
525d |
剝 |
1-15-94 |
| 繁 |
1-90-19 |
665a |
晚 |
1-85-28 |
fa35 |
卑 |
1-14-78 |
fa4b |
碑 |
1-89-07 |
| 賓 |
1-92-24 |
fa6a |
頻 |
1-93-91 |
fa41 |
敏 |
1-85-08 |
fa30 |
侮 |
1-14-24 |
| 倂 |
1-14-28 |
fa39 |
塀 |
1-15-58 |
fa33 |
勉 |
1-14-67 |
6b65 |
步 |
1-86-35 |
| 頰 |
1-93-90 |
fa3a |
墨 |
1-15-62 |
6bcf |
每 |
1-86-42 |
fa32 |
免 |
1-14-48 |
| 麵 |
1-94-80 |
f91d |
欄 |
1-86-27 |
f936 |
虜 |
1-91-47 |
6dda |
淚 |
1-86-83 |
| 類 |
1-94-04 |
623e |
戾 |
1-84-67 |
66c6 |
曆 |
1-85-39 |
6b77 |
歷 |
1-86-37 |
| 練 |
1-90-14 |
934a |
鍊 |
1-93-27 |
f928 |
廊 |
1-84-14 |
9304 |
錄 |
1-93-21 |
「𠮟、瘦、剝」の3文字は、JIS X 0213:2004で追加された文字のようです。
漢字コード
古い文書の電子化されたテキストを見ていて、久しぶりに文字コードに関心が向きました。
いつの間にかJIS0213になっていて、漢字は面区点コードで定められているようです。もはや、24x24ドットの漢字ROMと言ったことは完全に過去になったらしく、微細に思える字形の差が反映されているようです。
字形を主体としたUnicodeに対して、JISの文字コードの意味は、日本語の文字の分類にあると思います。実際に文書に使用された世界中の文字が利用可能と言うのは大変素晴らしいことです。しかし、かなやカナと言った文字種や、ソート順と言ったことは日本語の問題で字形の問題ではありません。こうしたことはJIS漢字コードの考慮すべき問題です。
異体字は、漢字圏に共通なものと、日本に固有のことがあります。また、特定の国で始まったことが、他国でも利用されていることがあります。
第三水準でもSJISが定義されているようです。SJISはJIS8単位文字列中にシフト無しでJISを配置することを意図して始まったものなのでsjisが分かれば区点を知ることもできると思います。現在のsjisは、shift_jis-2004のようです。
残念ながら今のところC#で扱えるコードページには無く、JIS X 0213:2004も不可です。
現状では面区点を知っても異字体などの情報が得られるわけではありませんが、shift_jis-2004を見てみます。
shift_jis-2004
JISの1面の割り当ての範囲で見てみます。
JISの区は94文字のようです。JISの区の番号は連番のようです。sjisはJIS8単位の未使用部分に最初のバイトを割り当てるので対応関係がデータとして必要です。
SJIS上下バイトとJISの区の対応
|
| - |
15 |
17 |
19 |
21 |
23 |
25 |
27 |
29 |
31 |
33 |
35 |
37 |
39 |
41 |
43 |
45 |
47 |
49 |
51 |
53 |
55 |
57 |
59 |
61 |
|
63 |
65 |
67 |
69 |
71 |
73 |
75 |
77 |
79 |
81 |
83 |
85 |
87 |
89 |
91 |
93 |
| 14 |
16 |
18 |
20 |
22 |
24 |
26 |
28 |
30 |
32 |
34 |
36 |
38 |
40 |
42 |
44 |
46 |
48 |
50 |
52 |
54 |
56 |
58 |
60 |
62 |
|
64 |
66 |
68 |
70 |
72 |
74 |
76 |
78 |
80 |
82 |
84 |
86 |
88 |
90 |
92 |
94 |
表は、上位バイトが0x87で、下位バイトが0x9fから0xfcのSJISコードは、JISの1-14-xxに当たると見ます。
青く塗った区は、JIS第一水準です。31あります。47区の51文字もJIS第一水準です。合わせて2965文字です。
赤く塗った区は、JIS第二水準です。36あります。84区の6文字もJIS第一水準です。合わせて3390文字です。
それ以外は、JIS第三水準です。
1バイト目が0xf0から0xfcは、JISの第2面で、JIS第四水準に割り当てられています。
言語識別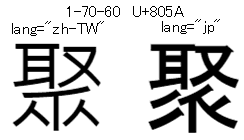
調べ始めた切っ掛けは左図のような差異でした。これは、文字コードによる異字体の話しとは別なものでした。
左図は、同じ文字コードですが、WEBページのHTMLタグのlang属性値で異なった字形が表示されます。
異なったフォントが参照されているのは確かだと思いますが、フォント名で切り替わる訳ではありません。同じことをブラウザ以外で行う方法も分かりません。
Unicodeのコード表の805Aには6つの字形があり、おそらく、T1-6A4D と J0-665C なのだろうと推測します。
字形が変わる仕組みはUnicode由来と言うことのようです。
JISの16進表記
J0-665C は、JISの最初の面の 0x665c と言うことだと思います。漢字フォントがROMで実装されていたころのパソコンの説明書にはコード表が付いていて、JISコードの欄は2121から始まり、「あ」は2422だったと思います。区点ではなく、JISの文字コードの「16進表記」を使っていたことになります。
区点表記からの変換は、1)上位バイト 区 + 0x20、2)下位バイト 点 + 0x20、ですが、区、点は通常10進表記なので16進に変換してから加算します。
u20b9f の「𠮟」は、面区点1-47-52 で、区=0x2f、点=0x34 です。16進表記は、4f54 です。
Unicodeのコード表では、u20b9f は「CJK Unified Ideographs Extension B」と言う名前の区画で、J3A-4F54 が「𠮟」のJISコードを指す名前です。
J3A-のプレフィックスの決め方は良く分かりません。「聚」は第二水準ですが、J0- なので、面でも水準でもないようです。
u6b9bの「殛」は、JISでは 2-78-01 で、2面の第四水準の漢字です。Unicodeでの文字の識別は J4-6E21 です。JISの2面でも同様に16進コードに変換できます。JISの2面は、2バイトの文字空間の重ならない場所(最初のバイトが0xf0以降)を割り当てているためです。
異体字の整理
周易の電子化したテキストは日本、台湾、中国でいくつか見ることができます。同じ箇所を多様な字形で表示します。底本の違いや、パソコンのフォントに引き当てる際の考え方の違いが反映されているものと思います。
インターネット上の検索では、異体字だけでなくカナ書きなどでも上手く検索してくれます。しかし、検索エンジンの知識がいつでも有効とは限りません。
比較のために異字体を統一したいと思いました。
同じUnicodeの異字体
前述のように、見た目の差異には、言語指定によるものがあり、これは文字コード上は区別がないので、これは変換することができません。
この異字体のデータはUnicodeのコード表自体が示しています。
異なるUnicodeの異字体
同じように使われる文字で、異なるUnicodeが割り当てられている文字には、意図的なものと、そうではない物に大別されると思います。
Unicodeの字形は、現在使用されているかどうかは問わないので、どの国でも、ほとんど使用されなくなった文字でも収録されます。
一方で、JIS漢字のように利用状況や歴史的経緯を調べて、コード化することが各国で行われています。新旧字の関係は、新字を定めた時に示されているはずです。
常用漢字表には前述の表の通り362文字に旧字が上げられています。弁だけは、辨瓣辯と3つの対応が挙げらえています。
それ以外には、下表のような関係が知られているようです。
常用漢字表に記載のない異字体
|
| 98f2 |
飮 |
98ee |
旧字 |
|
専 |
5c02 |
專 |
5c08 |
旧字。尃(5c03)は別字 |
| 9854 |
顏 |
984f |
曽 |
66fd |
曾 |
66fe |
曽は日本の略字 |
| 518a |
册 |
518c |
餅 |
9905 |
餠 |
9920 |
餅は俗字(漢字圏共通) |
| 820e |
舍 |
820d |
褒 |
8912 |
襃 |
8943 |
本字が定かでない文字らしい |
| 8217 |
舖 |
8216 |
翻 |
7ffb |
飜 |
98dc |
翻は俗字(漢字圏共通) |
| 6ca1 |
沒 |
6c92 |
覇 |
8987 |
霸 |
9738 |
覇は俗字(漢字圏共通) |
| 96b7 |
隸 |
96b8 |
闘 |
95d8 |
鬭 |
9b2d |
門構えではない時から作ったが漢字圏共通らしい |
漢字圏で共通なのは旧字なので、漢籍を旧字にすることには意味があります。しかし、個人的な利用なので新字体を取りたいと思います。
旧字体新字体の関係以外には有効なデータを知らないので、JIS第一水準、第二水準外の文字があったときに1つずつ調べて見ようと思います。
同じUnicodeの異字体のサポート
- <Grid>
- <StackPanel>
- <DockPanel>
- <TextBlock FontFamily="verdana" FontSize="64">聚</TextBlock>
- <TextBlock FontFamily="verdana" Language="zh-TW" FontSize="64">聚</TextBlock>
- <TextBlock FontFamily="verdana" xml:lang="zh-TW" FontSize="64">聚</TextBlock>
- </DockPanel>
- <DockPanel>
- <TextBlock FontFamily="verdana" Language="ja-jp" FontSize="64">聚</TextBlock>
- <TextBlock FontSize="64">聚</TextBlock>
- </DockPanel>
- </StackPanel>
- </Grid>

パソコンの「同じUnicodeの異字体」の表示がどうなっているのか少し試して見ました。
左図は WPF の XAML で表示したものです。
FontFamilyをMS ゴシックに設定しても上手くいきません。 VerdanaフォントはUnicodeに従っていて、字形も含まれていると言うことなのだと推測します。
これで、同じUnicodeの文字を言語指定で切り替えて1つのドキュメントに表示可能なことは分かりました。
WEBブラウザの機能ではなく、汎用的なものと理解して良いようです。
同じUnicodeを割り当てた意図は、それぞれのパソコンの言語設定に依って、適切な表示が行われるようにすることにあるものと思います。通常は同時に表示しなくて良いもので、見えているものは違うが、その方がより「同じ」ことが伝わるケースです。
日本では「与」と教える文字を、「与」と教える国があると言うだけのことです。
しかし、WEBページのlang指定は、この機能が働かないようにするものです。ページ内の表示を作成者が見ているものに固定します。他国で見ている人にも可能な限り作成者の見ている状態で見て欲しいと言う意図です。
また、引用を部分的に行うなどで、1つのページに両方を表示したいことは考えられます。これはxhtmlなら出来ることになっているようです。
HLMLタグ以外のタグに言語が指定できるのかどうか試してみます。 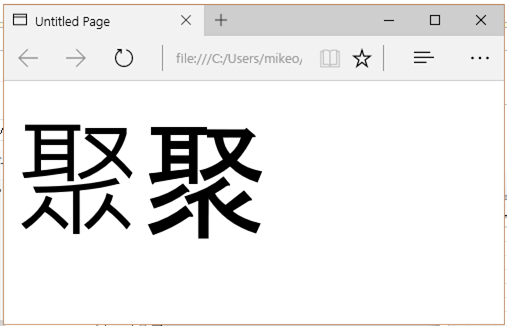
- <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
- <html xmlns="http://www.w3.org/1999/xhtml" xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml" xml:lang="ja-JP" lang="ja~JP">
- <head profile="http://a9.com/-/spec/opensearch/1.1/">
- <head>
- <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
- <meta http-equiv="Content-Style-Type" content="text/css" />
- <meta http-equiv="Content-Script-Type" content="text/javascript" />
- <title>Untitled Page</title>
- </head>
- <body>
- <div style="font-size:8em"><span lang="zh-TW">聚</span><span>聚</span></div>
- </body>
- </head>
- </html>
|