文字(char、int、string、BMP外のUnicode)
TestReader.Read()は、int型を返します。
char が16ビット(short)であることをやっと知りました。
Unicodeは、16ビットで表せないのでどうなっているのか見ます。
Visual Studio のエディタ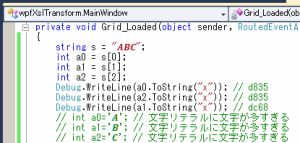
前に確かめたときには、対応がまだで、16ビットを超える値は □ と表示されていました。
現在は、表示できるようです。
確認は、IMEパッドでCanbria Mathフォントから、文字を選んで入力しました。
ワードが数式にBMP外のUnicodeを使っていますが、その際のフォントがCanbria Mathです。
フォントによって、含まれる範囲がことなり、実際には、多くのフォントがBMP外の領域に字形がありません。
Visual Studio のエディタが、選んだ文字の字形を正しく表示しているのは、どこかにフォントを選択する仕組みがあることになります。
C#のUnicode
上の図で "ABC" と表示されている文字は、それぞれ 0x1d468、0x1d469、0x1d46a です。
-
文字リテラルとして、BMP外の文字も記述できる。
-
それを元にstring型のオブジェクトを作れる。
-
しかし、siting[] は、char型で16ビットと規定され、取り出すことができない。
0xd835、0xdc68、0xd835、... と取り出される。
-
シングルクオートによる文字記述はエラーになる。
「文字数が多すぎる」と言うもの。
これは、C#がメモリ上にUTF-16エンコードで、Unicodeを保持していて、UTF-16では4バイトのサロゲートペアとして記録されていることによると考えられる。
Unicodeでは、0xd835、0xdc68 は、それぞれ上位の6ビットが、サロゲートペアの最初の10ビット、続く10ビットを示している。
上の図の続きに、以下のように記述して実行してみます。
- MemoryStream ms = new MemoryStream();
- StreamWriter sw = new StreamWriter(
- ms, System.Text.Encoding.UTF32);
- sw.Write(s);
- sw.Flush();
- ms.Seek(0, SeekOrigin.Begin);
- byte[] buf = new byte[ms.Length];
- ms.Read(buf, 0, (int)ms.Length);
- for (int i = 0; i < ms.Length; i++)
- Debug.Write(" " + buf[i].ToString("x"));
- Debug.WriteLine("");
- // TextReader.Read()の確認
- ms.Seek(0, SeekOrigin.Begin);
- TextReader tr = new StreamReader(ms);
- for (int i = 0; i < 3; i++)
- {
- int c = tr.Read();
- Debug.WriteLine(c.ToString("x"));
- }
UTF-32 エンコードで、文字列 s を、メモリストリームに書き込み、バイト単位に値を見ます。
また、TextReader.Read() を試します。
- ff fe 0 0 68 d4 1 0 69 d4 1 0 6a d4 1 0
- d835
- dc68
- d835
-
ff fe は、BOM。
以降、4バイトで1文字で、 0x1d468、0x1d469、0x1d46a を表す。
string型は、UTF-16 のサロゲートペアを正しく扱っていると考えらえる。
-
TextReader.Read() は、int型だが string と同様で、16ビット値しか返さない。
文字列でBMP外のUnicodeを扱うには
文字列をTextBlockなどで表示したりすることには特に問題が起きません。
おそらく比較なども問題ないものと考えられます。
問題があるのは、char型に変換して使う場合です。TextReader.Read()は int型ですが、実質は、実質はchar型のようです。
1文字を取り出して値を使う場合に問題が起きます。
文字列を記述する方法から見ます。
- // Canbria Mathフォントにある斜体、太文字のABC
- // Unicode
- string s = "\u1d468\u1d469\u1d46a";
- textblock1.Text = s; // 化けて表示
- // サロゲートペアで記述。
- string surrogate_pair
- = "\ud835\udc68\ud835\udc69\ud835\udc6a";
- textblock2.Text = surrogate_pair;// 正常に表示
- Visual Studio のエディタに、IMEパッドなどから直接ビジュアルに入力するのは問題ない
- 文字列リテラル中にエスケープで記述する場合、バックススラッシュ、u の後には4文字と決まっていて、5文字目は通常の文字と見なされ入力できない。
- サロゲートペアに変換し、1文字を2つに分けて記述するとOK
このことから、string や char は、アプリケーションがサロゲートペアを扱うことを前提にしたものだと推測できます。
しかし、多くの場合、これを知らずにプログラミングしても実害はありません。
サロゲートペアで表されるのが、BMP外の大きな値のコードで、サロゲートペアも16ビットの大きな値なので文字列の比較でも問題は起きないと考えられます。
表示される正確な文字数が必要な場合や、文字の値を直接演算する場合だけ特別に処理することになります。
char型の文字コードを上位6ビットを調べながら見ていき、サロゲートペアの上位下位を検出します。
unicodeに直すには以下のようにします。
- // サロゲートペアで記述。
- string surrogate_pair
- = "\ud835\udc68\ud835\udc69\ud835\udc6a";
- textblock2.Text = surrogate_pair;// 正常に表示
- char[] ca = surrogate_pair.ToCharArray();
- for(int i=0;i<ca.Length;i++)
- Debug.Write(string.Format(" {0:x}",(int)ca[i]));
- // d835 dc68 d835 dc69 d835 dc6a と表示
- int us = ca[0] >> 10; // サロゲートペアの識別(110110)
- int uu = ca[0] & 0x03ff; // Unicodeの上位10ビット
- int ls = ca[1] >> 10; // サロゲートペアの識別コード
- int lu = ca[1] & 0x03ff; // Unicodeの下位10ビット(110111)
- int unicode = 0x10000 | (uu << 10) | lu;
- Debug.WriteLine(
- us.ToString("x") + " " + uu.ToString("x") + " " +
- ls.ToString("x") + " " + lu.ToString("x") + " " +
- unicode.ToString("x"));
- // d835 dc68 d835 dc69 d835 dc6a36 35 37 68 1d468 と表示
また、バイト列をエンコードすることもできます。
- // サロゲートペアで記述。
- string surrogate_pair
- = "\ud835\udc68\ud835\udc69\ud835\udc6a";
- byte[] bytes = new byte[64];
- int charUsed;
- int bytesUsed;
- bool completed;
- Encoding.UTF32.GetEncoder().Convert
- (surrogate_pair.ToCharArray(), 0, surrogate_pair.Length,
- bytes, 0, bytes.Length, true,
- out charUsed, out bytesUsed, out completed);
- for (int i = 0; i < bytesUsed; i++)
- Debug.Write(" " + bytes[i].ToString("x"));
- // 68 d4 1 0 69 d4 1 0 6a d4 1 0 と表示
ファイルからの入力
TextReader.Read() は、int型で1文字を返すので、Unicodeの値が返ると期待しましたが、string と同様でした。
ファイルは、いろいろなコード系で作られています。
これは、TextReaderにエンコードの指定をすることで対応できます。
このエンコードは、入力のコード系を指定するもので、読み込まれる値は常にUnicodeです。
TextReader.Read() は、string[] に相当すると考えられ、文字列を入力する ReadLine() や ReadToEnd()は、stringと同様に正しくBMP外のUnicodeを処理しています。
後は、前述の文字列の処理をすることになります。
- // サロゲートペアで記述。
- string surrogate_pair
- = "\ud835\udc68\ud835\udc69\ud835\udc6a";
- // これをメモリストリームに書き込む
- MemoryStream ms = new MemoryStream();
- TextWriter tw = new StreamWriter(ms);
- tw.Write(surrogate_pair);
- tw.Flush();
- // 書き込まれたバイト列の確認(UTF-8エンコード)
- ms.Seek(0, SeekOrigin.Begin);
- for (int i = 0; i < ms.Length; i++)
- Debug.Write(" " + ms.ReadByte().ToString("x"));
- Debug.WriteLine("");
- // f0 9d 91 a8 f0 9d 91 a9 f0 9d 91 aa と表示
- // TextReader.ReadToEnd()でstring型に読み込む
- ms.Seek(0, SeekOrigin.Begin);
- TextReader tr = new StreamReader(ms);
- string str = tr.ReadToEnd();
- for (int i = 0; i < str.Length; i++)
- Debug.Write(string.Format(" {0:x}",(int)str[i]));
- // d835 dc68 d835 dc69 d835 dc6a と表示
- // UTF-16エンコードのUnicodeとして処理することになる
XPSからXAMLへの変換
(以下にUnicodeに関する過去の記録を併合しておきます。)
ワードで数式を記述して、XPS => XAMLファイルにして見ました。
数式中の a が、1d44e でした。(Cambria Math)
現象の説明
ワードで作成した数式をXSPで出力して、XAMLに変換しました。
出来上がったXAMLファイルはIEで正常に開け表示もXSPのビューアと同じです。
しかし、Visual Studio や テキストエディタで、このXAMLファイルを開くと、 "□" に表示されている箇所があるのに気が付きました。
(現在はVsisual Studio のエディタは正常に表示します。この当時からクリップボードへのコピーなどは正常にでき、表示以外は正常で、現在と変更がないと考えられます。)
そこで、この箇所をコピーして、下記のようなコードを実行して見ました。
- //□に化けている文字
- string s = "□";
- //デバッグ出力も□
- Debug.WriteLine(s);
- //WPFのWindowには a
- TextBlock tb = new TextBlock();
- tb.Text = s;
- canvas1.Children.Add(tb);
- //charが2つと判断される。 0xd835 と 0xdc4e
- char[] ca = s.ToCharArray();
- foreach (char c in ca)
- Debug.WriteLine(((int)c).ToString("x"));
- □ と表示されているが、クリップボードを介したコピーなど、Windowsは正常に扱う。
- Visual Studio のエディタ、出力ウインドウでは正しく表示できず、□になる。
- WPFの実行時の表示やデザイナ、プロパティ表示には正常に 'a' が表示される。
- このコードは、UnicodeのBMP(Basic Multilingual Plane)外で、string型は4バイトで保持している。
- しかし、siting やc har は、2バイトを前提に出来ていて、ToCharArray()は2文字にしてしまう。
- BlendのXMAL編集窓では、正しく表示できる。
BMP外のメモリ上の表現
前述の結果から、0xd835、0xdc4eを、2進表記します。
1101 1000 0011 0101 / 1101 1100 0100 1110
それぞれのワードの最初の6ビットは、UTF-16のサロゲートペアの識別コードになっているので削除します。
00 0011 0101 / 00 0100 1110
0000 1101 0100 0100 1110
0 d 4 4 e
が得られ、元の Unicde は、0x1d44e (119886) だったことがわかります。
パソコンのメモリ上では、35 d8 4e dc と格納されている物と考えられます。
少し不思議に感じたのは、4バイトの値をインテルCPUで格納したときとは異なることです。処理はあくまで2バイト、16ビットで行うものだと言うことでした。
XPSでの表現
元のXPS上では該当箇所は、以下のようになっています。
- <Glyphs Name="a17" BidiLevel="0" Fill="#FF000000"
- FontUri="/Resources/0CBB4DD8-44FB-2BF1-9E3C-D81B97648148.odttf"
- FontRenderingEmSize="10.56" StyleSimulations="None" OriginX="141.14"
- OriginY="184.7" UnicodeString="𝑎" Indices="(2:1)1853" xml:lang="en-US">
- </Glyphs>
BMP外のコードは、引用符で囲んだ文字列としての表現は、最初から諦めているようです。
&#で始まる十進数として表しています。
BMP外文字は注意を
プログラミング上は、charが16ビットであり、BMP内の Unicode の値が使われます。
このことから、パソコンのメモリ上では、文字列は UTF-16LE のようです。
UTF-16 は可変長ですが、BMP内なら16ビットで表現でき問題が起きません。
また、BMP外の文字を含んでも、表示やファイルへの入出力、クリップボードを介したコピーなども問題がありません。
多くの場合、文字列単位での比較やソートにも問題がありません。
問題が起きるのは、文字列をchar型の配列として扱う場合です。
- BMP外の文字は、char[]に変換すると1文字が2つになる。
- したがって、char数と文字数が一致しない。
- 0xd800からの、字形の割り当てられていない区間のコードが出現する。
- // サロゲートペアで記述。
- string surrogate_pair
- = "\ud835\udc68 x \ud835\udc69\ud835\udc6a";
- Debug.WriteLine(surrogate_pair.IndexOf("x")); // 3を表示
- Debug.WriteLine(
- surrogate_pair[surrogate_pair.IndexOf("x")]);
- // x が表示される
この例は、表示上ゼロから数えて2文字目にある "x" が、3文字目として認識されることを示しています。
多くの場合、このインデックスの示す値が "x" なら、2 でも 3 でも問題が起きないことが考えられます。
しかし、考慮してプログラミングしていないと、想定外の問題を生じることもあり得ます。
なぜエディタが表示できないのか
BMP外のUnicodeに付いて、OS側はすでに対応済みのようです。
表示できない場合は、アプリケーションが文字は16ビット超のUnicodeに対応していないことが考えられます。
また、フォントの選択の問題があります。
1つのフォントがすべての字形を持っていれば簡単ですが、実際にはフォントを切り替えないと表示ができません。
|