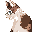DTDパーサー
以下のように考えて、パーサを作って、MathML の DTDを表示してみました。
Silverlightアプリケーションで、図をクリックすると実行します。
| MathML DTD の宣言 |
|
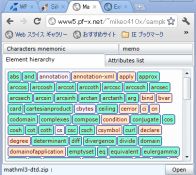
|
|
IE9もデフォルトではMathMLを表示しないようです。
SVGは表示できます。
そこで数式や図をSVGでHTMLにインラインすることにして見ようと考えました。MathMLをSVGに変換することを考えます。
MathMLの入力は、ワードや数式入力パネルなどからクリップボード経由でコピーします。
わたしは、MathMLもSVGも知らないので、DTD記述から、それぞれの構文を知ろうと思います。
-
DTDもXMLとしてパースできると思ったのですが、少なくともSilverlightのXmlReaderでは読むことができませんでした。
「 DTDの効果」
-
DTD記述自体の定義は、「Extensible Markup Language (XML) 1.0 (Fifth Edition)」に、BNFで記述されているもののようです。
XmlReaderはDTDを正しく扱いますが、DTD自体をドキュメントとして扱うことはできないようです。
DTDをパースするプログラムがあるはずですが、分からないので簡単なパーサーを作って調べます。
このパーサはXMLを読むのにも使います。「DTDの効果」で調べたことからすると、XmlReaderは、参照をすべて展開します。展開していない状態を取得したいと思います。
目的がMathMLの構文の理解なので、参照用に振られたシンボルには意味があります。
文字セット
パーサーを作る上で文字の表現方法が気になります。入力となるバイト列は、さまざまなコード系の可能性があります。
-
XMLドキュメントには XMLDecl が記されている。
-
MathMLのDTDには、XMLDeclがない。
-
プログラミング上ではUTF16エンコードのUnicodeを扱う。
MathMLのDTDは、ASCIIコードだけで記述され、どのエンコードと見ても、解釈が変わらないものだと思います。
また、DTD が Unicode なら、名前に、どの文字を使っても問題が起きません。解析に使われる '<' などのマークとは絶対に一致しないからです。
文字コードの問題は、いろいろなことが考えられますが、Unicodeだけを対象にしようと思います。
Unicodeについて
Unicodeだけを対象にしようと思いますが、すこし補足します。
SJISとUnicodeファイル
字形ごとに一意な数値を割り当てたものが文字コードですが、127以下の部分については、どのコード系でも、原則、同じ対応になっています。
Unicodeには、BOM(Byte Order Mark)が定められていますが、これがない場合は、127以下の文字だけからなるファイルは、SJISのファイルもUnicodeのファイルも同一内容だと言うことです。
テキストエディタで半角英数だけを書いて、SJISと、BOMなしのUnicodeで保存すると全く同じファイルになります。
0 から 127 の部分は、「Basic Latin」、「Ascii」などと呼ばれます。ISO646、JIS X 0201の1面、Latin1、ISO8859の前半と言うこともできます。
この範囲のコードだけが使われている MathML の DTDファイルの扱いには問題が起きないと言うことです。
ファイル上の表現とプログラムでの扱い
MathMLのDTDファイルは、Basic Latin の文字のみから成るので問題がありませんが、それ以外の文字が、プログラムでどのようになるのか見ておきます。
テキストエディタで、"あ" 1文字だけを入力し、
-
SJIS
-
UTF-8 BOMなし
-
UTF-8 BOM付き
-
UTF-16BE BOMなし
-
UTF-16BE BOM付き
の形式で、5つのファイルを作って読み込んでみます。
読み込む方法は、
-
Stream.ReadByte()
-
TextReader.ReadToEnd()
-
StreamReader.ReadToEnd()
- void FileDump(string fn)
- {
- Debug.Write(System.IO.Path.GetFileNameWithoutExtension(fn) + " : ");
- // ファイル上のバイト列を表示
- Stream f = File.OpenRead(fn);
- for (int i = 0; i < f.Length; i++)
- Debug.Write(f.ReadByte().ToString("x") + " ");
- // TextReaderで読み込んだ文字列
- TextReader tr = new StreamReader(fn);
- string s1 = tr.ReadToEnd();
- tr.Close();
- Debug.Write(s1 + " " + ((int)s1[0]).ToString("x") + " ");
- // StreamReader.ReadToEnd()で読み込んだ文字列
- string s2 = (new StreamReader(fn)).ReadToEnd();
- Debug.Write(s2 + " " + ((int)s2[0]).ToString("x") + " ");
- Debug.WriteLine("");
- }
- private void Grid_Loaded(object sender, RoutedEventArgs e)
- {
- FileDump(@"../../a_sjis.txt");
- FileDump(@"../../a_utf8.txt");
- FileDump(@"../../a_utf8_bom.txt");
- FileDump(@"../../a_utf16be.txt");
- FileDump(@"../../a_utf16be_bom.txt");
- }
結果は以下のようです。
- a_sjis : 82 a0 �� fffd �� fffd
- a_utf8 : e3 81 82 あ 3042 あ 3042
- a_utf8_bom : ef bb bf e3 81 82 あ 3042 あ 3042
- a_utf16be : 30 42 0B 30 0B 30
- a_utf16be_bom : fe ff 30 42 あ 3042 あ 3042
-
"あ" の Unicode は 0x3042 です。プログラムで扱うのは常にこのコードです。
プログラムで扱うUnicodeは、特にバイト数に決まりはなく、値と考えます。
Unicodeの値の最大は、0x10ffff。
-
Unicodeをメモリやファイルに格納する場合は、バイト単位に分割することになるので、文字の区切りが分かるようにする必要があります。
このためのエンコードが、UTF-8やUTF-16です。これらは1文字のバイト数は可変です。UnicodeをUTF-8にエンコードすると1文字は最大6バイトになります。UTF-16の場合は、2バイトか4バイトになります。
-
デフォルトはUTF-8で、BOMの有無にかかわらず読み込めます。
-
UnicodeならBOM(Byte Order Mark)があれば、エンコーディングに係らず読み込めます。
-
UTF-16BE BOMなしの場合、UTF-8と見なすので、0x30、0x42は半角2文字('0'、'B')として読み込まれました。
-
SJISの"あ" 0x82a0は、0xfffd として読み取られました。Unicodeの0xfffdは、REPLACEMENT CHARACTERと名前が付いています。
0x82が、字形を持つUTF-8の1文字目としては未使用なためだと思います。
ファイル形式とプログラムでの値
| ファイル形式 |
| 82 a0 |
☓ |
fffd |
| e3 81 82 |
〇 |
0x3042 |
| ef bb bf e3 81 82 |
〇 |
0x3042 |
| 30 42 |
☓ |
0x30 0x42 (2文字) |
| fe ff 30 42 |
〇 |
0x3042 |
BMP外のUnicode
TextReaderを使って読み出せば、Unicodeのデコードの問題はないと考えたのですが間違いでした。
「文字(char、int、string、BMP外のUnicode)」に記したように、プログラム上はUTF-16エンコードのUnicodeの処理が必要でした。
char型が16ビットです。TextReader.Read()の返す値は32ビットのint型です。
しかし、いずれも同じ値を返し、16ビット以上のUnicodeを表現できません。
string自体は、UTF-16エンコードで正しくUnicodeの処理を行います。
具体的には、読み出した16ビットの値が、サロゲートペアの先頭かどうかを見ることが必要で、サロゲートペアの場合、続く16ビットと合わせて、2つのchar型の値から1つのUnicodeにデコードすることになります。
あるいは、一括してUTF-32にエンコードすることも考えられます。
DTDのパッケージ
W3のページからMathMLのDTDをダウンロードすると、ZIPファイルで複数のファイルから成り立っています。
単に複数ファイルをまとめたものなのか、パッケージングのルールがあるのかはわかりませんが、ZIPファイルをフォルダとして扱うことになります。
パーサーの目的
Visual Studio のエディタでXMLファイルを編集する場合、DTD定義はリアルタイムに反映されます。DTDにしたがって、構文チェックが行われエラー箇所がマーキングされます。また、文脈依存で入力補完も機能します。また、参照の未定義も検出されます。「DTDの効果」
この場合、DTDは以下の機能を実現しています。
-
構文チェック
-
入力補助
-
文字の実体参照宣言
この場合、パーサーは、規格に忠実な解析が必要で、エラーが見つかっても解析を続けることになります。
ブラウザのように、表示が目的なら、規格に忠実でなくてもそれなりに表示される方が適切です。
今回は、MathMLからSVGへの変換に必要な構文情報をC#のコードの形で取り出すことが目的です。
基本的に入力にはエラーがないものとして、エラーがあればそこで打切るように作ります。
気になる点
作成する前に気になることを調べておきます。「文字(char、int、string、BMP外のUnicode)」
-
文字
- Char ::= #x9 | #xA | #xD | [#x20-#xD7FF]
- | [#xE000-#xFFFD] | [#x10000-#x10FFFF]
C#で文字として入力した場合、UTF-16エンコードのUnicodeとして扱うことになる。
C#のchar型は16ビットで、0xD800 - 0xDFFF の区間(Surrogate Area)はサロゲートペアに使われ、2つ char から、0x10000 - 0x10ffff の1つのUnicode 文字に変換される必要がある。
このことは、ファイルサイズやcharの数と、文字数が一致しないことを示し、読み込んで、サロゲートぺアを処理するまで文字数が分からないことを示す。
ファイルの先頭の0xfffe、oxfeff は、BOMに使われるので入力結果には反映されないものと考える。
SJISをUTF-8として読み込んだ場合は、前述の例のように 0xfffd などの、Charに含まれるUnicodeとして読み取られる。
-
Nameのハイフンとアンダースコア
XAMLでは、Nameは、アンダースコアが有効で、ハイフンが使えない。
XMLでは、先頭以外にハイフンが有効。アンダースコアは、先頭にだけ許される。
-
NameはAscii文字に限らない
- NameStartChar::= ":" | [A-Z] | "_" | [a-z] | [#xC0-#xD6]
- | [#xD8-#xF6] | [#xF8-#x2FF] | [#x370-#x37D]
- | [#x37F-#x1FFF] | [#x200C-#x200D] | [#x2070-#x218F]
- | [#x2C00-#x2FEF] | [#x3001-#xD7FF] | [#xF900-#xFDCF]
- | [#xFDF0-#xFFFD] | [#x10000-#xEFFFF]
- NameChar ::= NameStartChar | "-" | "." | [0-9] | #xB7
- | [#x0300-#x036F] | [#x203F-#x2040]
- Name ::= NameStartChar (NameChar)*
-
リテラル(文字列)
single-quotation と double-quotation は、それぞれペアで使い、等価。
single-quotationのペアは、double-quotation を普通の文字として含むことができる。
double-quotationのペアは、single-quotation を普通の文字として含むことができる。
-
リテラルの記述箇所による差異
・SystemLiteral
外部参照のDTDファイルを指す文字列は、前述のルールに従う。
・AttValue
属性値として記述される場合は、'&'、'<' を、普通の文字として含むことができない。
'&' は、 &name; のような参照と解釈される。
・EntityValue
Entityの定義のSYSTEM の値として記述される場合は、'&'、'%' を、普通の文字として含むことができない。
&name; や %name; のような参照と解釈される。
・PubidLiteral
Entityの定義のPUBLIC の値として記述される場合は、字類に制約がある。
- PubidLiteral ::= '"' PubidChar* '"'
- | "'" (PubidChar - "'")* "'"
- PubidChar ::= #x20 | #xD | #xA | [a-zA-Z0-9]
- | [-'()+,./:=?;!*#@$_%]
-
リテラルは、記述箇所が決められているので、その他では、
single-quotation 、double-quotation は、普通の文字として扱われペアとして扱われない。
-
MathMLのDTDは、「document」の構造になっていない。
これについて明確な記述はわからないが、extSubset が該当し、機能的には intSubset に準じると解釈して置く。
-
マークアップであるので、マークアップ記述と、マークアップされる対象がある。
マークアップされる対象は、CharData で、XMLの文字セットから、'<'、'&' を除外した文字列となる。さらに、"]]>" と言う文字列も除外される。
'<' は、マークアップ記述中に含まれるので、先頭から見ていく必要がある。
Comment、PI、CData、SystemLiteralに、入れ子はない。
-
'<' は、マークアップ記述の開始を示すことになるが、これに要素名が続くケースは、EmptyTag と、STag となる。
'/' が続く場合は、ETag となる。
'?' が続くのは、PI(Processing Instructions) となっている。"<?xml " も定義されていて、TextDecl、XMLDecl と名前が与えられている。
'!' が続く場合は、"<!" としては定義されていない。
-
"<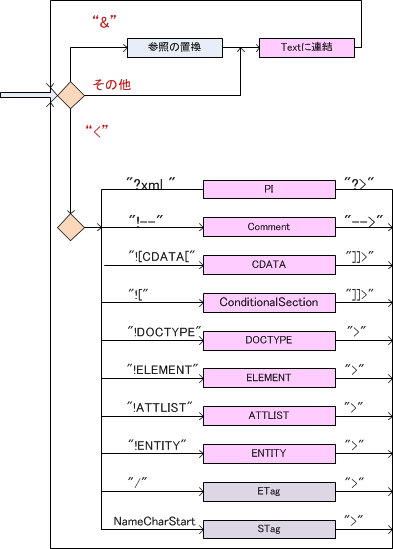
BNFに従って見ていくと AttDef で行き詰まりました。
そこで、少し離れて、左図のようなステートに分けて考えることにします。
最初のパースでは、出現順に、マークアップされる対象(Text)と、マークアップ記述を列挙することにします。階層はなく、マークアップ間の整合性も調べません。
このパーサーはXMLにも使いたいと考えています。両方を可にすると、バリデーションできないことになりますが、標準的な(エラーのない)ソースの内容把握が目的なので良しとします。
また、0x01 などは、XMLの対象外の文字ですが、除外文字はチェックしないことにします。
ステートへの遷移条件は、比較的明瞭ですが、ステートの終了条件は明瞭ではありません。
初期状態は、Text ステートとします。
マークアップされる対象の Text は、DTDの宣言では、インクルードしたファイルに書かれた定義を展開する目的で、参照を記述するのに使用されています。
これは、Text に %xxx; の参照(PEReference : Parameter-entity references)記述が有効だと言うことです。
Text部分は、CharData の繰り返しなので、& と < は除外されていますが、%は含まれます。
ただし、ここでは、この参照を展開しません。後の処理にゆだねることにして、ここでは他の文字と同様そのままTextに含めます。これは、参照名には意味があると考えるからです。記述した人は何かの基準で名前を付けて分類をしています。
ここでは、&で始まる参照(CharRef と EntityRef)だけを展開します。
展開前の状態で、< が出現すると Textステートを終わります。
< に続いて、タグ名が続くケースには、STag と EmptyElemTag があります。
終端が、/> の場合を EmptyElemTag とします。
</ に続いて、タグ名が続くケースはETagとして記録します。
ここでは、&で始まる参照(CharRef と EntityRef)を展開します。
引用符の認識を行います。引用符内の > は、終端と見なしません。
STag、EmptyElemTag、ETag は、DTDの記述には出てこないようです。
PI(Processing instructions)
実際に見かけたのは、<?xml と <?IS10744 です。
これは、?> までを無条件に切り出して記録します。
何の処理もしません。
ここには、エンコーディングが記されますが無視します。
UTF-8以外のエンコードが必要な場合は、その都度ユーザーがエンコードを選択するものとし、パーサーのオプションで指定することにします。
また、<?xml は、空白を伴って定義されていますが、空白文字なら可とします。
Comment
--> が出現するまでのすべての文字をコメントとして記録します。
DOCTYPE中に記述されることがあり、その場合はDOCTYPEの情報として記録します。
CDATA
]]> が出現するまでのすべての文字をCDATAとして記録します。
他のマークアップ記述中にも記述できます。
この場合は、単にCDATAの囲みが除去されるだけで、CDATAを独立に記録しません。
宣言
<! に続いて、宣言を記述するケースには、大別して DOCTYPEと、その他(DTDの記述に使われるELEMENT、ATTLIST、ENTITY、NOTATION)に分けられます。
DOCTYPE
DOCTYPEは、documentに関する記述で、DTDにはないようです。
DOCTYPEは、DTDを含むことができます。
ここでは、DOCTYPEはそのまま記録します。
ここでは、&で始まる参照(CharRef と EntityRef)を展開します。
引用符の認識を行います。引用符内の > は、終端と見なしません。
引用符外のブラケット( [ と ] )を認識します。
この中には、DTDの記述が可能で、PI、コメントも含まれます。
ここでは、%で始まる参照(PEReference)を展開します。
ENTITY
GEDecl と PEDecl があります。
対応する宣言は、それぞれ ENTITY名と、% ENTITY名です。
参照は、&ENTITY名; と、%ENTITY名; です。
PEDeclは、XMLファイルに読み込まれる、独立したDTDファイル内でのみ有効です。XMLファイルのDOCTYPE中以外に記述することはできません。
したがって、PEDecl定義は、最終的にはGEDeclで参照され、そのENTITY名で、&ENTITY名; のようにXMLで使われることになります。
ELEMENT
XMLの普通の要素名(タグ名)と、その形式を宣言します。コンテンツの有無と、入れ子になる要素を宣言します。
|
この要素はコンテンツを持たない。
EmptyElemTagを指すわけではなく、コンテンツが実際になければETagを伴っても良い。 |
| (子になる要素を限定しない場合に使われるようだ) |
入れ子になる要素名を | で区切って列挙する。
要素名には終端に、?、*、+ のいずれか1文字を置くことができる。?は省略可。*はゼロ回以上の繰り返し。+は1回以上の繰り返し。括弧で囲む。 |
| children と、#PCDATAやPEReference。括弧で囲む。 |
ATTLIST あるタグに指定可能な属性を宣言するものです。この情報は、その属性が必須かどうかや選択可能な値、省略時の値を設定できます。
この情報は、XMLエディタの入力支援やバリデーションに使われます。
<!ATTLIST elementName attributeName dataType default >
基本は、上のような形式です。
elementName のタグに記述する属性名 attributeName が、dataType 形式であることを示します。
この属性が必須であるか、省略時はどんな値と見なされるかは default によります。
1つの属性を、 attributeName dataType default の3つの項目で示します。
しかし、宣言の多いDTDファイルでは、多くが参照を記述しています。
例えば、すべてのエレメントにある、class や id などをまとめて定義したENTITYを参照するように記述します。
この場合のルールは明瞭ではないのですが、すべて独立に3つの組の単位で記述されると考えます。
DataType
| DataType |
| 文字列 |
|
| ID |
|
| IDの参照 |
|
| 複数のIDの参照 |
複数のIDが空白文字区切りで並ぶことを指す |
| 実体参照 |
|
| 複数の実体参照 |
複数の実体参照が空白文字区切りで並ぶことを指す |
| NMTOKEN |
|
| 複数のNMTOKEN |
NMTOKEN形式の文字列が空白文字区切りで並ぶことを指す |
| 複数のNMTOKEN |
(nm1 | nm2 | nm3)
の、ようにどれか1つが可と言うことを指す |
default
|
| 必須 |
不可 |
タグの記述時この属性を記述しないとバリデーションではエラーとなる。 |
| Option |
不可 |
記述しなければプログラムではこの属性は取得されない。 |
| Option |
必須 |
#FIXEDが宣言した属性は、タグの記述時にエディタの入力支援機能が宣言した値を自動挿入する。属性を記述しない場合、プログラムではDefaultValueを受け取る。DefaultValue以外の値を記述した場合は、記述した値を受け取る。そしてバリデーションではエラーとなる。 |
| Option |
必須 |
Enumeratedに列挙した値の1つを記述する。タグの記述時にエディタの入力支援機能でEnumeratedに列挙した値から選択できる。属性を記述しない場合、プログラムではDefaultValueを受け取る。DefaultValue以外の値を記述した場合は、記述した値を受け取る。 |
|