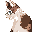マークアップとエンコード
マークアップがXMLに基づいて行われることは、始まったばかりなので当分続くことになると考えます。
経緯からHTMLはXMLではありませんが、WEBのページを作成する際にXMLだと思って作成しても特に問題は無いようです。
XMLであると言うこと
XMLを使ったプログラムを作成する観点で考えるとXMLには以下の特徴があります。
-
容量や計算速度の問題からプログラムが使用するデータは個別に設計され、文字列であっても、そのエンコード、デコードは個別の問題でした。
XMLでは、Encoding を記述するようになっていて、規格化されたエンコード、デコードだけが使われていると考えることができます。
-
データを構成する要素は、要素名、属性リスト、コンテンツと3つに大別され、アプリケーションは、この大別されたものをデータとして扱うことになります。
文字コードの現状
Windows NT は、最初から Unicode でした。Unicodeは長い歴史と変遷があります。
しかし、文字コードは、字形を示す番号なので、字形(フォント)がなければ実用にはなりません。
左図の、左の文字は、「ビー」と入力してかな漢字変換で変換して入力しました。
右は、IMEパッドを表示し、Cambria Mathフォントを選択した上で、1d505 にある文字をクリックして入力しました。
ともに B で、Unicodeでは、それぞれ「SCRIPT CAPITAL B」、「MATHEMATICAL FRACTUR CAPITAL B」です。
後者は、16ビットを超えるUnicodeですが、エディタもブラウザも問題なく扱ってくれます。
しかし、選択されたフォントが字形を持つかどうかは別な問題です。
フォントがない場合は、それを示す四角いマークなどの字形が表示されます。
ここでは、フォントを明示的に指定していません。したがって、Windows,IE9以外では、右(U+1d505)は、おそらく四角が表示され、「MATHEMATICAL FRACTUR CAPITAL B」の字形が表示されません。
ほとんどのフォントは、1d505のUnicodeに対応するフォントを持っていません。
Windows上でも、普通に使う「MS ゴシック」などのフォントには、1d505 がありません。
Canbria Math フォントには、1d400-1d7ff の間の字形があります。
IEにはコードの値によって自動的にフォントを切り替える仕組みがあるようです。
Silverlightアプリケーションでは、「Portable User Interface」と言うフォントが使われますが、このフォントには、1d400-1d7ff の間の字形も含まれています。
-
Unicodeのすべての字形を持つフォントは存在しないらしい
-
一般的なフォントは英数の範囲 か sjis の範囲の字形を持つ
-
したがって、sjis の範囲の文字だけを使うか、フォント指定を明示するかの選択になる
-
フォントを明示したくても、フォントはパソコンごとに事情がことなる
-
XPSのように、使用されている字形だけからなるフォントファイルを作成したり、フォントをサーバーからダウンロードする仕組みがあるようだが一般的ではない
-
ブラウザ側が持つフォントファミリを、マークアップで指定する方法では結局問題は解決しない。
-
書体の違いでも、形の違うものには別のコードを割り当てるUnicodeは、この問題がないが、実際にUnicodeの文字を完備に表示できる状況にはない。
-
フォントファイルの選択ではなく、書体の指定なら、Unicodeとも相容れる。
プログラミングの際のUnicode
System.Text.Encoding.Unicode のように、Unicodeの名前を持つものがあります。
プログラミング上のUnicodeは、UTF16エンコードを意味しています。
これに対して、多くの場合 「『あ』の Unicode は U+3042」 と言うと、エンコードされていないUnicodeを指しています。
『あ』の場合は、UTF16エンコードしても、同じ 0x3042 です。
前述の U+1d505 の場合は、0xd835、0xdd05 と4バイトにエンコードされます。
IMEパッド上で Cambria Mathフォントを選択して、1d505 の位置の文字の上でマウスポインタをホバーリングすると、「unicode: U+D835 U+DD05」と表示されます。
エンコードされていないUnicodeは、字形をナンバリングしたもので「値」です。
これを、ファイルやメモリに記憶するには、文字ごとの区切りが分かるようにする必要があります。
例えば、すべて4バイトの固定長で記録することができ、これがUTF32エンコードです。4バイトごとに整数値とすれば、エンコードされていないUnicodeの値と同じになります。
多くの文字が1,2バイトであることを考えると冗長なので、可変長で格納することが考えられます。これが、UTF8、UTF16です。この場合、単に整数化しても、元のエンコードされていないUnicodeにはならないことになります。
また、表記上のU+の有無もエンコードの有無の区別にはなりません。IMEパッドの例のように、UTF16エンコードされたサロゲートペアの両方にU+ を付けて表記しています。
Unicodeが定めたのは、フラクトゥール書体のB に、U+1d505 と言う番号を振ることだと思います。フラクトゥール書体のB のUnicodeは、U+1d505 で、この数値をUTF16エンコードのルールで変換すると、0xd835 と0xdd05 の2つの16ビット数値が得られると解釈します。
エンコードされたものは、UTFxxエンコードされたUnicodeと明記するようにしたいと思います。
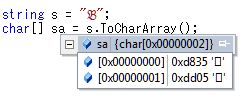
Visual Studio のエディタなら、IMEパッドから入力すれば U-1d505 の文字も他の文字と区別なく入力も表示もできます。
しかし、プログラムでは1文字として扱われません。プログラムで扱うのは、UTF16エンコードのUnicodeです。
C#の場合、Unicodeで記述するときも、2文字分記述することになります。
以下のように書くと、0x1d50 と、数字の5が記されていると解釈されます。
「文字(char、int、string、BMP外のUnicode)」参照。
BOM、XML宣言
Unicodeでは、ファイルの先頭にBOM(Byte Order Mark)置くことができます。
また、XMLでは、ファイルの先頭がXML宣言で始まることになっています。
しかし、ファイルの内容のエンコードを正確に知る方法が決められていないことも事実です。
BOM(Byte Order Mark)
Unicodeでは、feff をBOMとしています。ファイルの先頭の4バイトを見ると以下のようなケースに分けられます。
| 先頭の4バイト |
| UTF8 |
feff をUTF8エンコードすると ef bb bf の3バイトのコードとなる。
UTF8にはバイトオーダによる差異は起きない。(BOMはUTF8を示していて、バイトオーダを表さない。) |
| UTF32 |
ビッグエンディアンであることが分かる(格納順が1234) |
| 使用されない(格納順が3412) |
| 使用されない(格納順が2143) |
| リトルエンディアンであることが分かる(格納順が4321) |
| UTF16 |
最初の2バイトでビッグエンディアンであることが分かる |
| 最初の2バイトでリトルエンディアンであることが分かる |
| BOMなしかUnicode以外 |
正常なテキストファイルであると言う前提で、ファイルの内容から判定することになる |
- BOMがバイトオーダーを示すのは、UTF16とUTF32のとき
- BOMがある場合、正常なテキストファイルなら SJIS や EUC などの他のコードとの区別にもなる
- ASCII文字からなるファイルは、どのコード系でも同じなので内容から区別はできない。
たとえ、どのコード系と解釈したとしても問題が起きないと言う考え方。
XML宣言
XMLファイルの先頭には、XML宣言が置かれ、encodingを記述できます。
ファイルの先頭は '<' から始まっているはずです。もし、空白文字がないとすれば、以下のようになります。
| 先頭の4バイト |
| UTF32 ビッグエンディアン |
| UTF32 リトルエンディアン |
| UTF16 ビッグエンディアン |
| UTF16 リトルエンディアン |
| UTF8かUnicode以外 |
正常なテキストファイルなら、SJISもEUCもゼロを割り当てないので表のような区別が付きます。
XML宣言では、以下のようにencodingを記述できます。
<?xml version="1.0" encoding="Shift_JIS"?>
これは、ファイルの中に書かれているものなので、読み出して見るまで分かりません。
この部分は、ASCII文字しか使われないので、UTF8でも、SJIS、EUCでも差はありません。
エンコードの処理
XML宣言はないことも、記述ミスもあり得ます。
エンコードを識別する方法には決定打はなく、実用的な方法を選択することになります。
最初の選択は、文字を扱うか、バイト列を扱うかです。
ここでは、コード系に応じて処理を変える必要性はないので文字を扱うことで考えます。
TextReader や StreamReader の ReadToEnd()でstring型に読み込むか、TextReader.Read()で1文字ずつ読み出します。
取得される文字は、入力ファイルのエンコードとは関係なく、UTF16エンコードのUnicodeです。
この方法は、入力がBOM付きのUTF32、UTF16、UTF8 と、BOMのないUTF8のファイルを正常に読み込むことができます。
これ以外のエンコードのファイルを読み込むには、StreamReaderをコンストラクトする際にエンコードを指定します。
あらかじめ、エンコードを知る必要があります。
XML宣言があるならそれを利用できますが、多くの場合、使われていないように見えます。
BOMの有無を調べ、BOMがない場合は、ASCII以外の文字を探します。
ASCII文字だけなら、UTF8と見なして処理します。
それ以外は、各コード系の特徴から判断することになります。
UTF16の処理
ファイルのエンコードからの変換は、TextReaderで行うことができますが、読み出されるのは、エンコードされていない本来のUnicodeではなく、UTF16エンコードされたUnicodeです。
-
MathMLのDTDのように多くにファイルはASCIIコードだけでできています。
この場合は、エンコードの問題はありません。
-
エンコードされていないUnicodeが16ビット以下の文字しか使われていないなら、正しいエンコードを指定して読み込んだstringやcharのデータは、エンコードされていないUnicodeに等しく、扱いに特別な配慮はいりません。
-
使用されている文字に制約がない場合、サロゲートペアを処理する必要があります。
サロゲートペアの処理
UTF32エンコードのBOM付ファイルを作ります。
ファイルの内容は、前述の「MATHEMATICAL FRACTUR CAPITAL B」 U+1d505 です。
最初の4バイトは、BOMです。
- TextReader tr = new StreamReader("file.txt");
- char c1 = (char)tr.Read();
- if (char.IsSurrogate(c1))
- {
- char c2 = (char)tr.Read();
- if (char.IsSurrogatePair(c1, c2))
- {
- Debug.WriteLine(((int)c1).ToString("x")
- + " " + ((int)c2).ToString("x"));
- Debug.WriteLine(
- (0x10000 | ((c1 & 0x3ff) << 10)
- | (c2 & 0x3ff)).ToString("x"));
- }
- }
これを実行すると、以下のようになります。
-
TextReader.Read()はint型ですが、16ビット以上の値を返すようにはできておらず、charと同じ16ビットまでの値を返します。
-
読み込んだcharが、サロゲート文字なら、次のcharを読みます。
2回の読み取りで取得した2つのchar型のデータ(d835 と dd05)が1文字(1d505)を表します。
-
2つのサロゲートペアを1文字にするには演算が必要です。
サロゲートペアを含む文字列の処理
int型に変換
以下のようにすると、入力ファイルから読み出されたUTF16エンコードのUnicodeを、エンコードされていない本来のUnicodeでint型の配列に格納できます。
- string s = (new StreamReader("file.txt")).ReadToEnd();
- MemoryStream ms = new MemoryStream();
- TextWriter tw = new StreamWriter(ms, new UTF32Encoding(false,false));
- tw.Write(s);
- tw.Flush();
- ms.Seek(0,SeekOrigin.Begin);
- int[] unicode=new int[ms.Length/4];
- BinaryReader br=new BinaryReader(ms);
- for(int i=0;i<unicode.Length;i++)
- unicode[i]=br.ReadInt32();
- foreach (int c in unicode)
- Debug.WriteLine(c.ToString("x"));
int型の配列にすると、文字数と配列の長さが一致します。
サロゲートペアを意識せず、比較などができます。
- if (unicode[0] == 0x1d505)
- {
- }
しかし、string型の恩恵が受けられません。Split() や Substring() などを作る必要があります。
サロゲートペアのまま扱う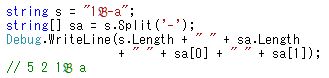
実はstringにサロゲートペアを含んでも多くの操作は問題が起きません。
カンマで区切るためにSplit()を呼び出すことや、IndexOf()でコンマの位置を知ることは問題が起きません。
これは、サロゲートペアのそれぞれは、他の文字と一致することがないためです。
問題が起きるのは限られた操作です。
ここで挙げる例は、"1B-a" の、 4文字の文字列 s です。ここで、B は U-1d505 (フラクトゥール書体のB)と考えてください。
この s.Length は、5 で文字数を示しません。しかし、ハイフンでスプリットすることは問題ありません。
s,IndexOf('-') とした場合、2ではなく3が返ります。しかし、s[3]がハイフンなので多くの場合問題が起きません。
-
フラクトゥール書体のBは1文字ですが、2つのcharと見なされ、シングルクオートで囲んで記述することができません。コンパイルエラーです。
if(s[1]=='フラクトゥール書体のB'){}
-
以下のように書くことはできますが、警告となります。また、実行しても一致することはありません。
U-1d505 は、UTF16エンコードで、s[1] に 0xd835、s[2]に 0xdd05 となって格納されています。
-
以下の比較は成功します。
- if(s.Substring(1,2)=="\ud835\udd05"){}
-
「ハイフンの前の文字」を以下のようにして取得できません。1文字の後半の 0xdd05 が取得されます。
- string x = s[s.IndexOf('-') - 1].ToString();
-
「ハイフンの前の文字」を正しく取得するには以下のようにする必要があります。
- int p = s.IndexOf('-');
- string x;
- if (char.IsLowSurrogate(s[p - 1]))
- x = s.Substring(p - 2, 2);
- else
- x = s[p - 1].ToString();
MathML中の文字参照
ワードは数式をクリップボードにMathMLでコピーできます。また、MathMLを張り付けることもできます。
前述のフラクトゥール書体のB は、以下のように文字参照で表せます。
- <mml:math xmlns:mml="http://www.w3.org/1998/Math/MathML">
- <mml:mi>𝔅</mml:mi>
- </mml:math>
この場合は、サロゲートペアなどで記述することはありません。
また、Windows上ならIMEパッドなどでビジュアルに入力できるので文字参照を使う必要もありません。
以下のように記述することもできます。
- <mml:math xmlns:mml="http://www.w3.org/1998/Math/MathML">
- <mml:mi mathvariant="fraktur">B</mml:mi>
- </mml:math>
数式パネルから入力した場合、クリップボードに入れられるMathMLには、以下のXML宣言が付いています。
- <?xml version="1.0" encoding="utf-16" ?>
パソコン内部での文字コードはUTF16エンコード状態なのでこの記述はそれを反映したものだと思います。しかし、これをUTF-8に書き換えても何んの影響もないようです。
内部的には使われることはないようです。
多くの場合、ファイルに出力する際には、UTF8エンコードが使われます。
この際には、XML宣言のencodingをUTF-8にすることが必要です。
|